
 HBase 예제 살펴보기~
HBase 예제 살펴보기~
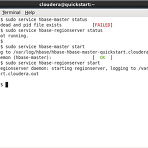
이번에는 클라우데라에 포함된 HBase에 대해서 살펴보도록 하자. HBase에 대해서는 하둡(Hadoop) 관련 기술 - 피그, 주키퍼, HBase에 대한 간략한 정리! 를 참고하기 바란다. HBase 서버 확인 먼저 HBase 서버가 동작 중인지 확인해 봐야 한다. HBase는 Master와 RegionServer가 모두 동작해야 하므로 다음 명령어로 상태를 확인하고 동작 중이 아닌 경우, start 명령어로 시작하면 된다. > sudo service hbase-master status > sudo service hbase-regionserver status > sudo service hbase-master start > sudo service hbase-regionserver start HBase 실..
 [QuickStartVM] 하둡 word counting 테스트
[QuickStartVM] 하둡 word counting 테스트
클라우데라의 QuickStart VM을 활용해서 하둡 맵리듀스를 처리하는 예제를 살펴보기로 하자. 만약 VM이 설치되어 있지 않다면, QuickStart VM 설치하기 글을 참고하기 바란다. 테스트할 예제는 가장 기본적인 WordCount 예제이다. 해당 소스에 대한 설명은 WordCount 맵리듀스 테스트 글을 살펴보기 바란다. Word Count 테스트 이제 QuickStart VM을 통해서 Word Count를 해보기로 하자. 1. VM에서 터미널을 열고 다음 명령어로 hadoop-mapreduce-examples.jar 파일이 있는 곳으로 이동하고 해당 파일을 확인한다. > cd /usr/lib/hadoop-mapreduce/ > ls *examples.jar 2. hadoop jar 명령어로 w..
 HDFS 간단히 살펴보기~
HDFS 간단히 살펴보기~
"클라우데라 QuickStart VM 설치 후 먼저 HDFS 명령어를 통해 하둡 파일시스템에 파일을 올리는 간단한 예제를 살펴보고, Hue 인터페이스로도 확인해 보기로 하자. 1. VM에서 상단의 터미널 아이콘을 클릭한다. 2. 터미널에서 testfile.txt를 생성하고 하둡 파일시스템에 업로드한다. HDFS의 ls 명령어로 실제 파일이 업로드 된 것을 확인할 수 있다. 3. 이제 웹 브라우저 기반의 HUE 인터페이스를 통해서 해당 파일을 살펴보자. 웹브라우저의 북마크에서 Hue를 클릭하고 우측 상단의 "File Browser"를 선택한다. 여기에서도 testfile.txt 파일이 올라가 있는 것을 확인할 수 있다. 4. testfile.txt 파일을 클릭하면 해당 파일의 상세 내역을 볼 수 있다. 또..
 클라우데라 QuickStart VM 설치하기
클라우데라 QuickStart VM 설치하기
클라우데라에서 하둡 에코 시스템의 테스트를 위한 QuickStart VM을 제공하고 있다. Hadoop 2.0, Spark, Hive, Pig, HBase, Sqoop, Flume 등 하둡 관련 시스템을 일일이 설치하지 않고 가상환경에서 마음껏 테스트 할 수 있는 환경을 제공한다. 또한 사전에 포함된 데이터를 통해서 각종 기능을 테스트할 수 있는 "Getting Started"도 있으므로 하둡에 관심이 있으면 한번쯤 설치해서 사용해보기 바란다. QuickStart VM 다운로드 및 설치 QuickStartVM은 VMWare, KVM, VirtualBox의 VM으로 각각 제공되는데 VirtualBox를 통해서 설치해보기로 한다. 1. https://www.virtualbox.org/wiki/Download..
 구글, 페이스북, 링크드인, 야후, 클라우데라, 아파치의 빅데이터 스택 비교
구글, 페이스북, 링크드인, 야후, 클라우데라, 아파치의 빅데이터 스택 비교
아파치 진영을 중심으로 하둡 기반의 다양한 어플리케이션을 통해서 실시간 처리, 기계학습, 그래프 분석 등을 수행하고 있다. 하둡의 기본 개념이 구글 시스템에서 시작된 만큼 먼저 구글의 분산 처리 구성을 살펴본다. 그리고 아파치에서 제공하는 하둡 에코시스템의 구성을 알아본 후, 클라우데라, 페이스북, 야후, 링크드인 등에서 이를 활용하는 구조를 정리해 본다. 결국 회사의 용도에 맞춰서 기술들을 잘 조합해서 사용하는 것이 관건인 듯하다. 물론 필요에 따라 클라우데라의 임팔라나 링크드인의 카프카와 같이 직접 만들수도 있지만 말이다. 구글 빅데이터 스택 구글은 Chubby라는 'Coordination'을 사용하고, 데이터스토어로는 Big Table을 쓰고 있다. 그리고 맵리듀스의 상위 언어로 Sawzall을 사..
 Cloudera Impala - 하둡 기반의 SQL 쿼리 엔진으로 실시간 분석을
Cloudera Impala - 하둡 기반의 SQL 쿼리 엔진으로 실시간 분석을
Cloudera Impala 소개 Cloudera Impala는 SQL 형태로 Hadoop의 데이터를 이용해 실시간으로 분석할 수 있는 시스템이다. 이것은 MapReduce 프레임워크를 사용할 때, 배치 처리로 인한 지연이 발생하는 것을 최적화 한 것이다. 구글에서도 2006년부터 기존의 GFS와 MapReduce에 실시간 처리가 가능한 Dremel을 본격적으로 활용하고 있다. Apache Hadoop의 HDFS와 MapReduce가 구글의 GFS, MapReduce 논문을 기반으로 만들어진 것처럼, Cloudera Impala도 2010년 발표된 구글의 Dremel 논문을 기반으로 하고 있다. 다만, SQL과 유사한 형태를 하둡에서 활용하기 위해 Hive의 쿼리 방식의 인터페이스를 가져왔다. 하둡을 C..